|
I am a research scientist at Nvidia Deep Imagination Research. Before that I was a research scientist at Fundamental AI Research (FAIR), Meta. I obtained my Ph.D. in Computer Science from Texas A&M University, under the supervision of Nick Duffield. Email / Google Scholar / Github / LinkedIn / Twitter |

|
|
|
|
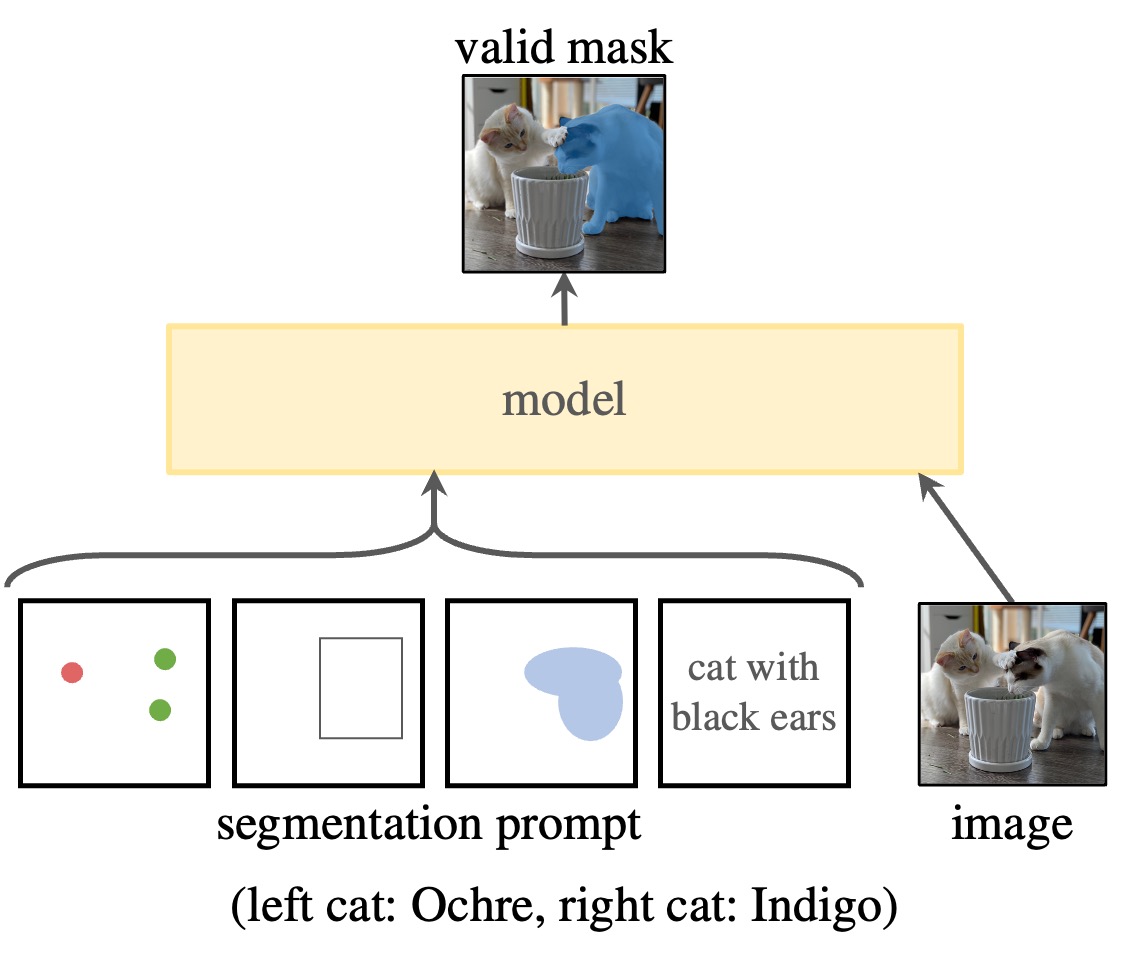
Alexander Kirillov1,2,4, Eric Mintun2, Nikhila Ravi1,2, Hanzi Mao2, Chloe Rolland3, Laura Gustafson3, Tete Xiao3, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar4, Ross Girshick4 ICCV, 2023. Best Paper Honorable Mention paper / project / dataset / code A new task, model, and dataset for image segmentation. |
|
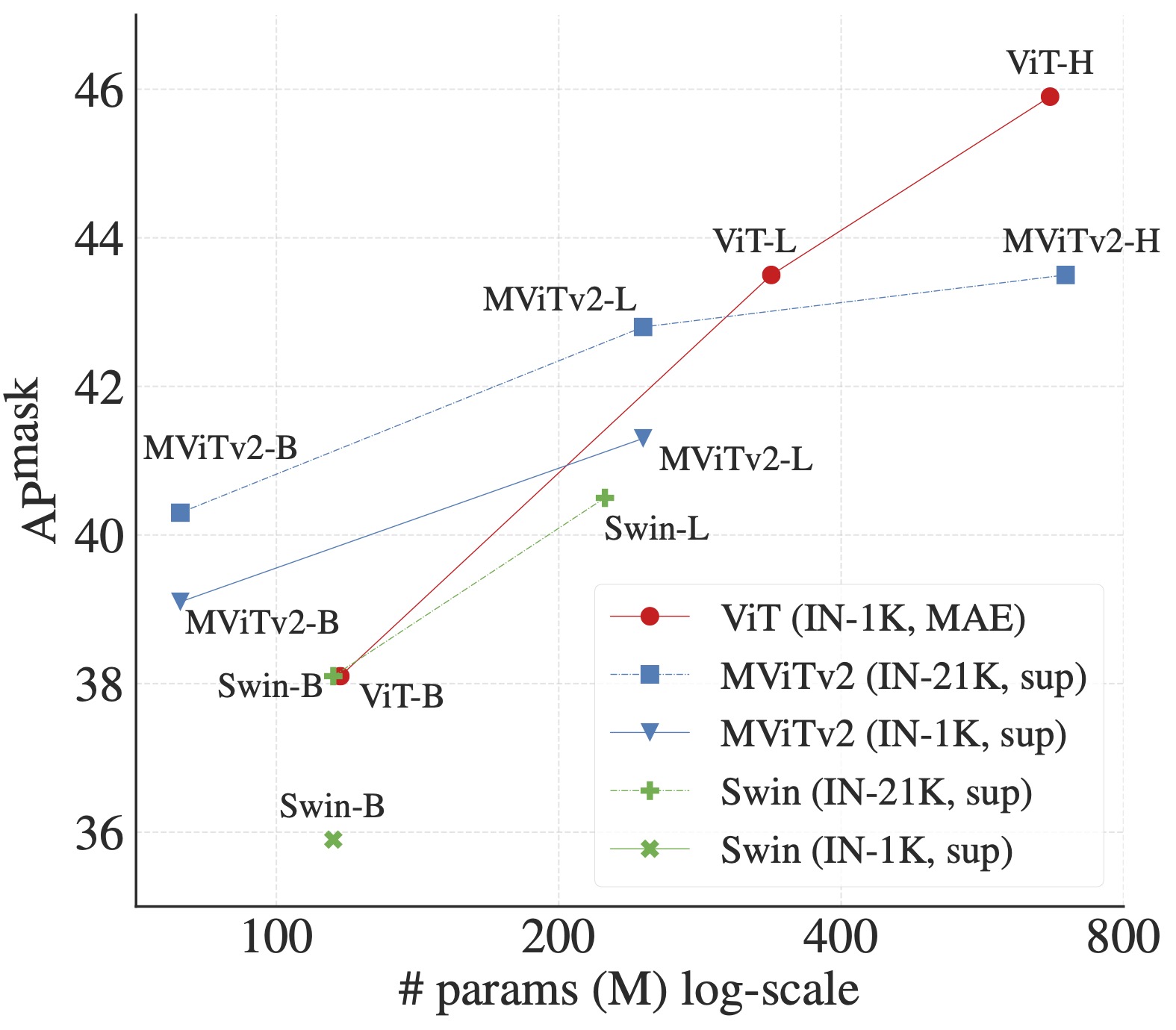
Yanghao Li, Hanzi Mao, Ross Girshick†, Kaiming He† ECCV, 2022. paper / code / blog A plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. |
|
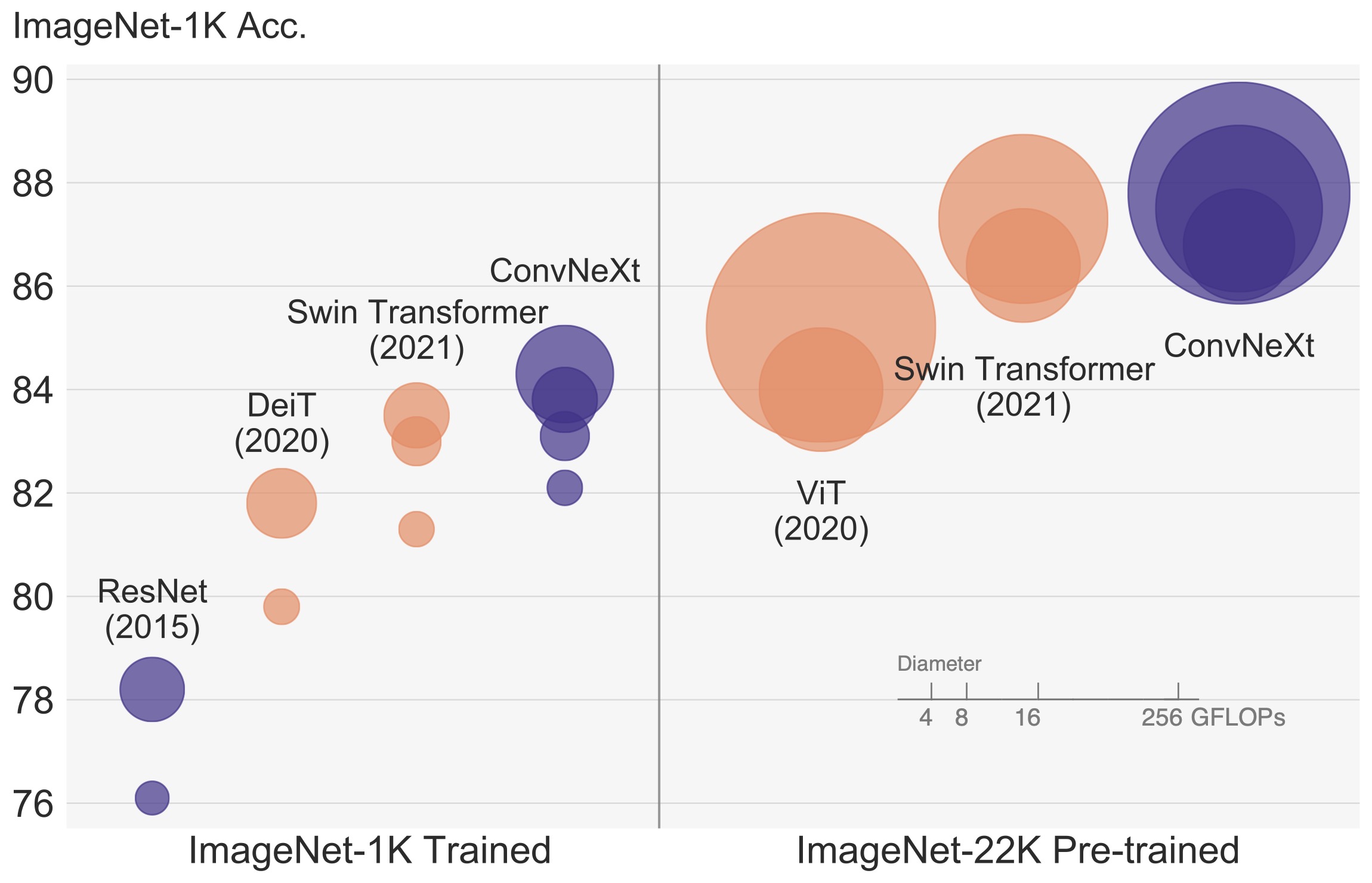
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie CVPR, 2022. paper / code A pure ConvNet model constructed entirely from standard ConvNet modules. ConvNeXt is accurate, efficient, scalable and very simple in design. |
|
Hanzi Mao, Xi Liu, Nick Duffield, Hao Yuan, Shuiwang Ji, Binayak Mohanty ICDM, 2020. paper / code A novel semi-supervised attention-based deep representation model that learns context-aware spatiotemporal representations. |
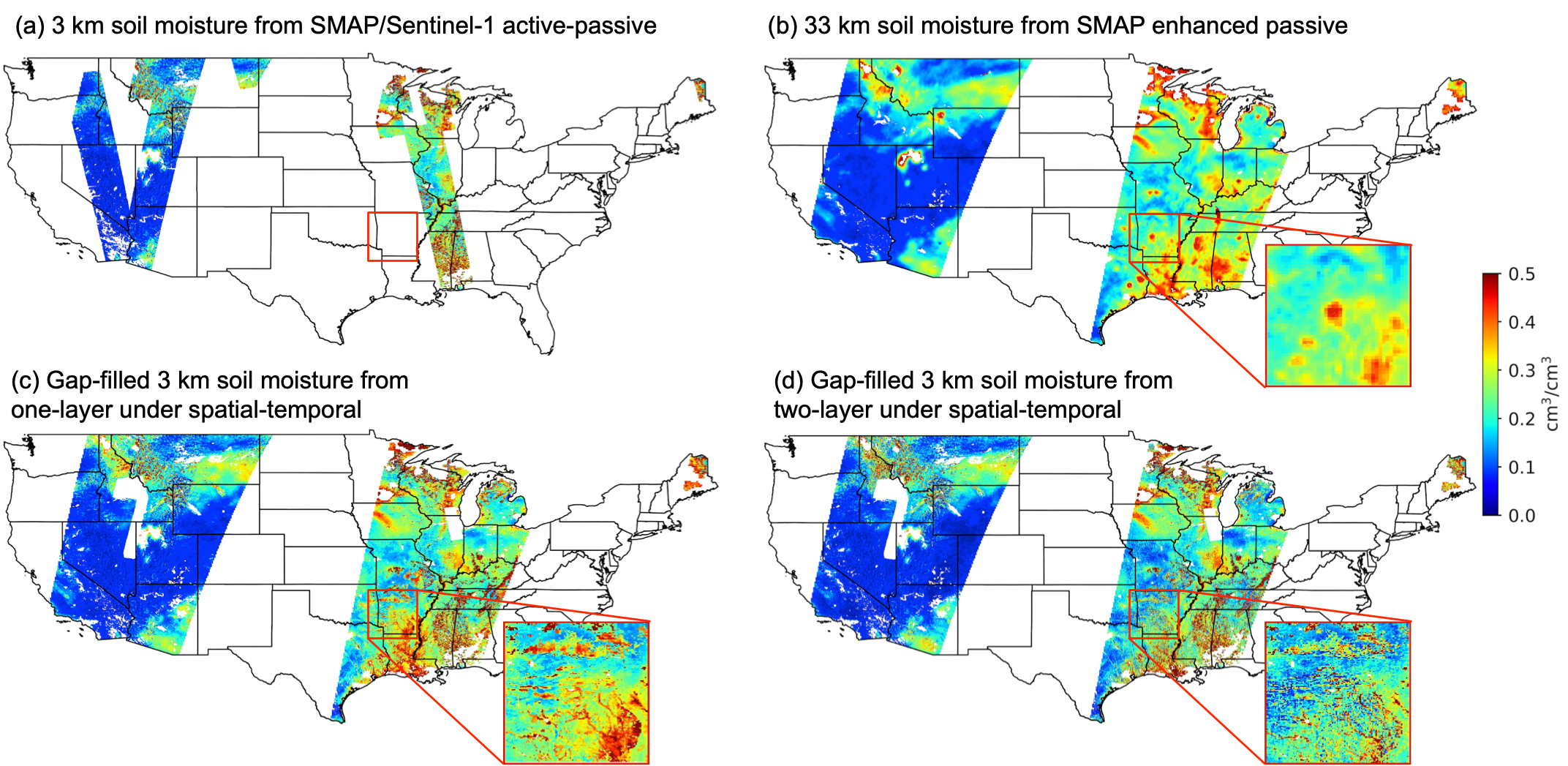
|
Hanzi Mao, Dhruva Kathuria, Nick Duffield, Binayak Mohanty Water Resources Research, 2019. paper / code A new gap‐filled soil moisture product to address the poor spatial and temporal coverage of the SMAP/Sentinel‐1 product. |
|
|